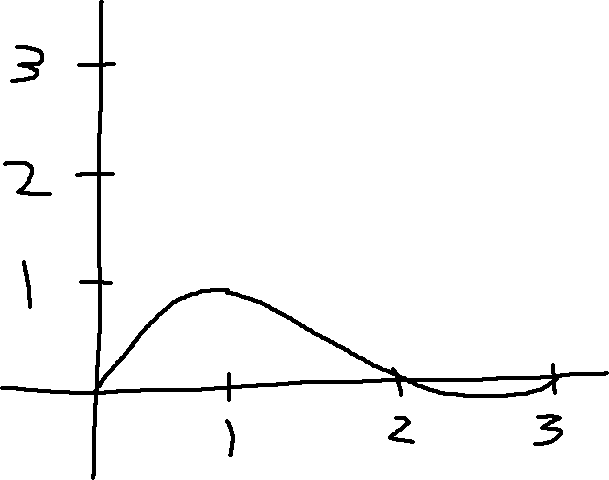
We first create a Lagrange polynomial for each data point.
This polynomial will equal 1 when the polynomial is passing through its respective point, but 0 when passing through other data points.
For all other points in-between, it’ll be some interpolated value we won’t care about.
Lagrange polynomial for some data point at x=1
These polynomials only contribute to their own data point.
What’s the purpose of this?
After finding the Lagrange polynomial of each data point, we can construct the Lagrange interpolation, a polynomial that goes through all the data points.
To do this, just multiply each Lagrange polynomial by its respective point’s y-value to make it pass through its data point. Then, add every term together.
That’s all getting a bit ahead of ourselves though, let’s return to formalling defining a Lagrange polynomial.
More formally, we want to construct a function:
l_i (x) = \begin{cases}
1 &\quad x = x_i, \\
0 &\quad x = x_j, j \ne i
\end{cases}
Making a polynomial equal to zero at certain points is easy.
For example, the polynomial y(x) = (x-a)(x-b)(x-c) is obviously zero when x is a, b, or c.
Suppose you have some data points: x_0 = 0, x_1 = 1, x_2 = 2, and x_3 = 3.
How would you make a polynomial that follows the “one at my point, zero at the other points” rule?
Focusing on x_2 as a concrete example, making the polynomial equal zero is easy:
l_2^* (x) = (x-0) (x-1) (x-3)
This work-in-progress polynomial follows the zero rule, but doesn’t yet equal one at its respective point.
To do that, we just have to divide the polynomial by itself, but replace x with i in the denominator (in our example, i=2).
The simplification is a bit tedious, but essentially it’s just a ton of duplicated operations to solve for a bajillion constants. Lagrange interpolation is more of an academic curiosity, so we’ll stop here.
In the next method, we’ll factor out the constants from Lagrange and focus on another way to get the interpolation polynomial.
Shows rate of change of slope to curve the polynomial to hit the third point (x_2).
Further — The numerator just calculates the difference between two slopes (between points 1 and 2, and points 0 and 1), and is divided by the range of outer points (x_2 - x_0).
To add a new entry to the table, you must calculate two parts:
Numerator: Use the values from the column immediately to the left. Subtract the value diagonally above from the value diagonally below (above and below are relative to the target cell)
Denominator: Trace those two numerator values diagonally back to the very first x-column. Subtract the top-most x value from the bottom-most x value.
As a concrete example, here is a simple construction for easy data set:
Note — If you remember the rules/reasoning for the terms (e.g., must equal zero at other data points), there are no formulae to remember. Re-read Lagrange if you don’t get this step!